Author: Andrew Tolton
Introduction – Khanmigo, LLMs, and AI in Education
Artificial Intelligence is a word that one doesn’t go a day without hearing in 2023. Recent breakthrough developments in Large Language Models (LLMs) and image generation have led to an explosion of research and innovation on how and where to best use these tools—from improving productivity in the workplace to facilitating materials research. One particularly exciting developing field is the use of LLMs in education.
In his TED Talk “How AI Could Save (Not Destroy) Education,” Sal Khan, the founder of the online learning platform Khan Academy, proposed the idea of using LLMs to provide students with a personalized online private tutor (Kahn, May 2023). Kahn argues that LLM tutors could help combat Benjamin Bloom’s 2 Sigma Problem, which says that students taught by a one-to-one tutor using mastery learning techniques perform 2 standard deviations better than students in the classroom (Bloom, 1984). To bring this goal to reality, Khan Academy has developed Khanmigo, their own AI tutor chatbot built in collaboration with OpenAI and powered by GPT-4.0 (Figure 1).
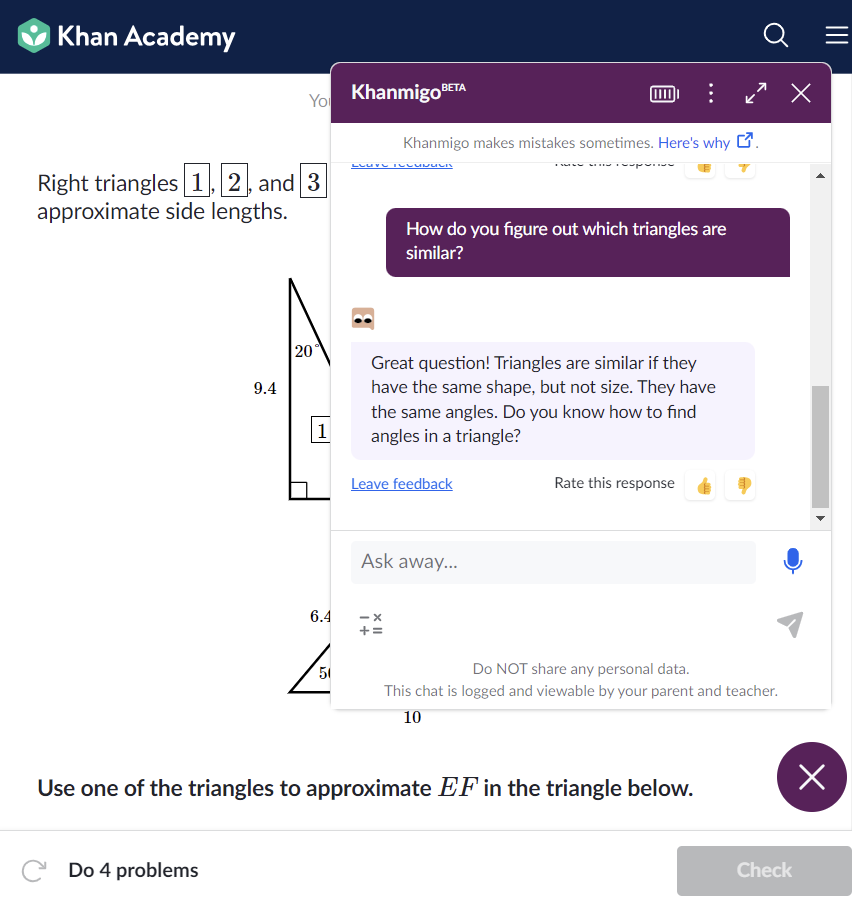
Figure 1: Screenshot showing a user interaction with Khanmigo within a lesson about similar triangles in Khan Academy. Khanmigo is Khan Academy’s AI tutor and helps students learn how to do problems and understand course concepts.
While Khan Academy’s mission is admirable, LLMs suffer from many deep-rooted flaws that hinder their capability as tutoring agents. Particularly dangerous in a tutoring environment—LLM’s create compelling, well-reasoned, incorrect answers. These are called “hallucinations,” and are currently an unsolved feature of LLMs. Additionally, most current LLMs don’t act like tutors. In their recent paper “Generative Large Language Models for Dialog-Based Tutoring: An Early Consideration of Opportunities and Concerns,” Nye et al. report the following major differences between typical AI and human tutoring dialogs:
- Human tutors take initiative and guide the conversation, whereas when engaging with AI tutors students learn through open-ended question answering.
- Human tutors ask questions of their own to students and prompt them to think instead of simply responding to student questions.
- Human tutors have pedagogical domain knowledge, meaning they know common misconceptions, pitfalls, and techniques that may help the student learn. An AI tutor with generic domain knowledge may lack these capabilities.
All together, these strategies form an effective tutoring dialog, and we refer to them as initiative, guided-questioning, and pedagogical domain knowledge, respectively. Human tutors use effective tutoring dialogs to help give the student a firm understanding of the material before moving on to other subject matter—the foundation of mastery learning. In contrast, typical LLM dialogs cast LLMs agents as chatbots and assistants, leaving the dialog to be user-led. There is little research showing learning-gains from user-led question answering, and thus AI tutor dialogs should try and mimic the 3 effective tutoring dialog traits (ETDTs) discussed above.
Despite these obstacles, Khan Academy has put significant resources towards developing Khanmigo to be a safe and effective tutor for its students. Since Khanmigo is built upon GPT-4.0., these efforts should have improved its ability to tutor students, but this improvement has not been tested. In this audit, we aim to quantify the difference in tutoring ability between Khanmigo and GPT-4.0, establish the efficacy of LLM online tutors, and understand what future improvements may be possible.
Research Questions
We pursue this goal through the following research questions:
- RQ1 – What is the difference in learning gain between GPT-4.0 generated hints and Khanmigo generated hints?
- RQ2 – Is Khanmigo more likely than GPT-4.0. to engage in effective tutoring dialogs?
- RQ3 – Is Khanmigo more likely than GPT-4.0. to be respectful to a diverse set of users (across cultural, linguistic, and gender norms).
Blue-Sky Audit
The Blue-Sky audit establishes an audit plan for a fully funded and staffed study. By performing the Blue-Sky Audit, researchers would be able to answer RQ1-3 to scientific standards, and the findings would be recorded and published. The Proof-of-Concept audit is a smaller and easier version that has been conducted to evaluate the ability of the Blue-Sky audit to answer the research questions. The Blue-Sky audit will take a deep look at each research question using the strategies described below.
RQ1: Learning Gain Analysis via Mechanical Turk
In their paper “Learning Gain Differences Between ChatGPT and Human Tutor Generated Algebra Hints,” Pardos and Bhandari established a framework for calculating the learning gains of ChatGPT and human tutor generated hints. They first selected a set of elementary and intermediate algebra exercises with human-generated hints from OpenTutor. For each of these exercises, they used ChatGPT to generate an alternative set of hints. Using Mechanical Turk, they then assigned participants to these exercises and gave them access to either the human or ChatGPT generated hints. Participant pre-performance and post-performance was evaluated, and the learning gains from human and ChatGPT generated hints were compared.
For the Blue-Sky audit, the Blue-Sky researchers would perform an exactly analogous analysis comparing the learning gains from Khanmigo and GPT-4.0. generated hints.
RQ2: Tutoring Dialog Analysis via LLM Trio
As discussed in the introduction, we expect AI and human tutoring dialogs to differ in 3 important ways, which we call the effective tutoring dialog traits (ETDTs): initiative, guided-questioning, and pedagogical domain knowledge. To answer RQ2, Blue-Sky researchers would evaluate the probabilities that GPT-4.0. and Khanmigo achieve effective tutoring dialogs. This would be done by recording how often they demonstrate all 3 ETDTs, qualified by the questions below.
To perform this evaluation on a large scale, Blue-Sky researchers would take advantage of techniques demonstrated by Nye et al. In addition to analyzing tutoring dialogs, Nye et al. additionally demonstrated the capability for ChatGPT to grade short-answer responses and act as a student to generate training data for tutoring models. Using this technique, a large-scale experiment could be established to generate dialog between a student and tutor model, and use a grader model to grade the tutor model on the following concepts:
- Did the tutor model take initiative and guide the conversation?
- Did the tutor model ask the student questions of its own (not just rephrase the problem)?
- Did the tutor model demonstrate pedagogical domain knowledge (understanding of common misunderstandings and use of multiple techniques to help students learn)?
A random sample of this data would be reviewed by human reviewers to gage the accuracy of the grader model. With sufficient accuracy, the study would proceed to evaluate the difference in effectiveness of tutoring dialogs from GPT-4.0. and Khanmigo.
RQ3: Respectful Conduct Analysis via Guest Auditors
To successfully gauge the respectfulness of GPT-4.0. and Khanmigo across a diversity of identities and norms, Blue-Sky researchers would hire auditors from various cultural, linguistic, and gender backgrounds to engage in mock tutoring dialogs with GPT-4.0. and Khanmigo. These auditors would then report whenever they feel they have been disrespected. Additionally, these “guest auditors” would test both GPT-4.0. and Khanmigo on topics they feel inappropriate and report on whether or not the LLM responded appropriately. The performance of GPT-4.0. and Khanmigo would then be compared.
Proof-of-Concept Audit
The (aptly named) Proof-of-Concept Audit was performed by the author (me!) as a proof-of-concept for the Blue-Sky audit. Because of restricted access to GPT-4.0. at the time of writing, the Proof-of-Concept audit had to use ChatGPT instead of GPT-4.0. as a comparison to Khanmigo. This introduces additional confounding variables because Khanmigo is built on top of GPT-4.0, and not GPT-3.5. like ChatGPT. We must keep this in mind before attributing the strengths of Khanmigo to the actions of Khan Academy.
In a Proof-of-Concept attempt to answer RQ1-3, I did exercises on Khan Academy and got tutoring help from both ChatGPT and Khanmigo. For each tutoring dialog, I recorded the Khan Academy problem, the tutor query, and the entire conversation history. Additional parameters were recorded to evaluate RQ1-3:
RQ1: Relative Learning Gain The relative learning gains were established by recording the relative usefulness of the Khanmigo dialog compared to the ChatGPT dialog. The Khanmigo dialog was rated as either better than (1), equal to (0.5), or worse than (0) the ChatGPT dialog. These ratings were informed by experience as a student and tutor, and my knowledge of the exercise subject domains. Instances of hallucination were also recorded.
RQ2: Manual Tutoring Dialog Analysis Each tutoring dialog from ChatGPT and Khanmigo was evaluated for effectiveness using the 3 questions from the Blue-Sky audit RQ2 procedure. If a tutoring dialog demonstrated an ETDT, that trait was recorded as true (1) for that dialog, and if not it was recorded as false (0). By recording ETDT capabilities, as well as relative learning gains, as numbers 0-1, I was able to generate a score to compare each AI tutor. These scores are given in the Results section.
RQ3: Respectfulness Flagging Throughout the investigation, if a tutoring dialog was determined to be disrespectful or inappropriate, it was recorded. This was done for both questions asked in English and Spanish.
An important note—auditing process took shockingly longer than expected, and so I only have data for a set of 10 Khan Academy exercises, 5 about high school trigonometry and 5 about 8th grade language arts. This is a small sample size, and makes it hard to make quantitative conclusions. Finally, to give an effective comparison between the tutoring capabilities of ChatGPT and Khanmigo, ChatGPT was pre-prompted with simple tutoring instructions and with relevant exercise parameters. The pre-prompt text is given in Figure 2 below:
| System: You are a tutor helping a student. You shouldn’t give them the answers to the problems they are working on, but instead guide them toward the right answer. You may need to give examples of simpler problems to help the student learn. You should be positive and encouraging to help the student learn. The student is working the following problem: — You shall help the student work to the correct answer without giving it to them directly. Student: — |
Results
The results from analyzing all 20 English tutoring dialogs are summarized in Table 1. Each AI tutor was evaluated across 5 questions from two topics, Trigonometry and Language Arts. For individual tutoring dialogs, each ETDTs was marked 1 or 0, where 1 means the AI tutor demonstrated the given ETDT, and 0 means they did not. The Hallucination Score was given a value 1-0 where 1 means there were no hallucinations, 0 means the AI tutor supported an incorrect answer, and values in between means they made a mistake of varying intensity. The relative rating compares the usefulness of Khanmigo’s tutoring dialog to ChatGPT’s, where for an individual dialog, 1 would mean better, 0.5 equal, and 0 worse. Table 1 gives each AI tutor a score in each of these areas by averaging these values across each exercise.
Due to the time of the collection process, results for Spanish tutoring dialogs were done only qualitatively. Both models were able to both handle requests in Spanish and respond in Spanish. Both models were also able to accommodate different student names. Because of the one-on-one interaction between the AI tutor and the student, names were not used unless requested, and there was no use of pronouns, ever.
The full student-tutor dialogs for every topic, AI, and language combination was saved in full, as well as the full dataset from which the summary scores were calculated. Access to this data is available at request to the author.
| AI Tutor | Subject | Hallucination Score | ETDT-1: Initiative | ETDT-2: Guided-Q’s | ETDT-3: Pedagogy | Relative Rating |
| Khanmigo | Math | 1 | 0.4 | 0.4 | 1 | 0.6 |
| Khanmigo | Lang | 0.8 | 0.2 | 0.2 | 0.6 | 0.3 |
| ChatGPT | Math | 0.8 | 0.2 | 0.2 | 0.8 | — |
| ChatGPT | Lang | 0.45 | 0.6 | 0.6 | 0.6 | — |
| Hallucination Score | How well each AI did at avoiding hallucinations and wrong answers. |
| ETDT-1: Initiative | How often each AI took initiative during the tutoring dialog and led the student. |
| ETDT-2: Guided Q’s | How often each AI guided the student with questions of its own. |
| ETDT-3: Pedagogy | How often each AI demonstrated knowledge of alternate ways of teaching a concept, or understanding of reasons a student may be confused. |
| Relative Rating | Avg. comparison of Khanmigo tutoring dialog to ChatGPT tutoring dialog. (1 = Always Better, 0.5 = Equal, 0 = Always Worse) |
Discussion
By analyzing the data from the Proof-of-Concept audit, we can field an answer for each of our research questions. We will start by discussing each AI tutor’s ability to achieve effective tutoring dialog, as this was important to their ability to achieve learning gains.
RQ2: Effective-Tutoring Dialog Analysis
Both AI tutors only ever achieved a single effective tutoring dialog (meaning they demonstrated all 3 ETDTs), and they did so for the same Khan Academy exercise. Additionally, the effectiveness of each AI tutor seemed heavily dependent on the way the student asked for help. When the student asked for help with a specific topic or made an error with a specific concept, both AI tutors would give the correct answer for that specific misunderstanding and end the conversation. However, if the student asked for help more generally, the AI tutors seemed to form much more effective dialogs. For example, the query that led to both tutors achieving effective tutoring dialogs was “Let’s talk through this question.”
We will discuss the rest of the effective-tutor dialog trait results in the context of each ETDT.
ETDT-1 : Initiative
To not beat around the bush: I expected Khanmigo to do better in this category. Both Khanmigo and ChatGPT seemed to perform quite similarly here, with average scores of 0.3 and 0.4, respectively. Both would occasionally take initiative to guide the student’s learning, but most often would be passive actors in the dialog, responding to questions from the student and then repeating the exercise question. The most initiative was taken by ChatGPT for exercises in language arts, where it guided discussions with the student and often asked them to consider various aspects of a given text. Khanmigo showed less initiative for language arts than it did for math exercises.
As mentioned earlier, this was dependent on the phrasing of the question by the student, but an effective human tutor would take initiative of all dialogs to ensure that the student understands a concept before just giving them the answer.
ETDT-2 : Guided Questions
The ability for the AI tutors to ask questions to guide the student ended up matching exactly the AI tutor’s ability to take initiative. This is because every time either AI tutor took initiative, it would lead the conversation Socratically by asking the student to consider subcomponents of the problem. However, when the AI didn’t take initiative of the conversation, it would simply give an explanation of a topic and then repeat the exercise question to the student.
ETDT-3 : Pedagogical Domain Knowledge
Surprisingly, both AI tutors were able to demonstrate pedagogical domain knowledge in a majority of tutoring dialogs. They typically demonstrated ETDT-3 by offering alternative methods for the student to think about a topic outside of the main method of discussion. However, neither tutor typically offered these alternatives on their own, even after several rounds of dialog with a student not understanding a topic. Instead, the student had to ask the tutor for another way to think about the problem, and only then would the AI tutor offer an alternative.
Hallucinations : The Accuracy Factor
The final consideration in comparing the effectiveness of Khanmigo’s and ChatGPT’s tutoring dialogs is accuracy—how often did either model hallucinate and support false answers? This was ChatGPT’s downfall—it would easily be talked into supporting a wrong answer and would often start supporting an incorrect answer all on it’s own. Khanmigo did hallucinate once during a language arts question, but overall it performed significantly better than ChatGPT in this category.
An additional note—ChatGPT hallucinated the MOST when it was engaging in effective tutoring dialogs! ChatGPT did a great job at taking initiative and asking the student questions for language arts exercises, but when the student would give ChatGPT their thoughts, ChatGPT would often agree and help support the student’s opinion, even if it was wrong. It would be interesting to see if this behavior could be mitigated through better pre-prompting.
Total Dialog Scores
To answer RQ2, I averaged over the hallucination score and all 3 ETDTs for both AI Tutors and called this the dialog score. Khanmigo achieved an average dialog score of 0.575, and ChatGPT achieved an average EDT score of 0.531. So, after accounting for hallucinations, Khanmigo was slightly more likely than ChatGPT to demonstrate effective tutoring dialogs.
RQ1: Relative Learning Gains
The relative learning gains offered by each AI tutor was quantified using the relative rating score in Table 1. The score compares the usefulness of Khanmigo’s tutoring dialog to ChatGPT’s. For an individual dialog, a score of 1 means that Khanmigo’s was better, 0.5 means they were equal, and 0 means Khanmigo’s was worse. Table 1 shows the average of these scores.
With this in mind, we see that Khanmigo’s tutoring dialogs were pretty comparable to (albeit slightly worse! than) ChatGPT’s—the average across both math and language arts exercises is 0.45. However, Khanmigo seemed to give slightly better tutoring dialogs for math exercises, while ChatGPT gave better tutoring dialogs for language arts exercises.
It should be noted that Khanmigo has native access to the Khan Academy environment and so it knows the exercise problem parameters without needing to be told by the student. ChatGPT however, as an external tool, needed to have all of the figures transcribed and readings copied in order to have the context needed to help the student. With this in mind, I find it quite incredible that ChatGPT was able to perform so well with its tutoring dialogs.
RQ3
As mentioned in the results, some of the math exercises were repeated with the student asking questions in Spanish instead of in English, but the analysis was only qualitative. Both models seemed perfectly capable with generating Spanish output, and their behaviors seemed similar to that of English output. I would have tested whether this remained true for Spanish language arts studies, but Khan Academy doesn’t have language arts in Spanish. Additionally, there were no incidents of disrespect or inappropriate behavior by either AI tutor. The one notable interaction: when the student asked Khanmigo to be referred to as Adolf, Khanmigo refused and ended the conversation, whereas ChatGPT happily obliged. However, when the student said their name was Adolf, both AI tutors were okay with it.
Discussion Summary
Shockingly, Khanmigo performed very similarly to ChatGPT as an AI tutor for lessons on Khan Academy. ChatGPT gave more useful and effective tutoring dialogs, but hallucinated rather often, becoming a slightly less effective tutor. Khanmigo gave less effective tutoring dialogs, but it seemed to hallucinate very infrequently—definitely a technical achievement by Khan Academy. Both models were well behaved when it came to interacting with the student appropriately.
Conclusions – Progress Unclear
It is important to note that these findings are based on a small study using crude techniques as a proof of concept. Regardless, the results of this Proof-of-Concept audit are surprising and somewhat worrisome for the future of Khanmigo and GPT-spinoff models. Khanmigo runs on GPT-4.0. and currently costs $7 a month to access because of the massive energy demands of GPT-4.0—does it make sense for students to pay to access an AI tutor that performs similarly to the free LLM ChatGPT?
Khanmigo does have some things going for it—it hallucinates infrequently, and it also has native access to the Khan Academy platform. To use ChatGPT, a student would have to accurately describe the entire problem to the AI tutor, and for exercises involving figures and diagrams, this can be tricky and time intensive. Khanmigo also has knowledge of Khan Academy video lesson concepts and can learn to fit a student’s needs over time.
So is Khanmigo worth it to students? And are Khan Academy’s efforts and investments working; is Khanmigo getting better and can it help push toward Khan’s goal of “provid[ing] a free, world‑class education for anyone, anywhere”?
To answer these questions, as well as to truly understand the differences between Khanmigo and its base model GPT-4.0., the Blue-Sky audit would need to be conducted. While the sample size for this study was low, the results from the Proof-of-Concept audit indicate that the answers to these questions may be surprising and important. Organizations across the world are currently building their own platforms on top of GPT-4.0. This audit begs the questions, can technologies built on top of LLMs overcome the shortcomings of the LLMs themselves? The answer to this question is crucial to not only achieving accessible personalized online education, but to achieving the responsible use of AI worldwide.
Works Cited
Bloom, Benjamin S, July 1984, Educational Researcher. 13 (6): 4–16. “The 2 Sigma Problem: The Search for Methods of Group Instruction as Effective as One-to-One Tutoring” (PDF). doi:10.3102/0013189×013006004. S2CID 1714225. Retrieved 4 Dec. 2023.
B. Nye et al., July 2023, CEUR Workshop Proceedings, “Generative Large Language Models for Dialog-Based Tutoring: An Early Consideration of Opportunities and Concerns,” https://ceur-ws.org/Vol-3487/paper4.pdf. Retrieved 18 Nov. 2023.
S. Khan, May 2023, YouTube, “How AI Could Save (Not Destroy) Education”, https://www.youtube.com/watch?v=hJP5GqnTrNo&ab_channel=TED. Retrieved 18 Nov. 2023.
Z. Pardos, S. Bhandari, Feb. 2023, Arxiv, “Learning Gain Differences between ChatGPT and Human Tutor Generated Algebra Hints,” https://arxiv.org/abs/2302.06871. Retrieved 18 Nov. 2023.